Decision Making and Control

Many outdoor enviroments are unstructured and spatiotemporal which can cause uncertain behavivors of robots. For example, the motion of aquatic vehicles in the water or aerial vehicles in the air can be highly uncertain/stochastic. The decision making (or planning under uncertainty) allows a robot to effectively reject action stochasticity caused by external disturbances.
Variants of Model Predictive Path Integral Control:
To address challening control problem, we haved developed a Uncented Model Predictive Path Integral (U-MPPI) control strategy, a new methodology that can effectively manage system uncertainties while integrating a more efficient trajectory sampling strategy. The core concept is to leverage the Unscented Transform (UT) to propagate not only the mean but also the covariance of the system dynamics, going beyond the traditional MPPI method. As a result, it introduces a novel and more efficient trajectory sampling strategy, significantly enhancing state-space exploration and ultimately reducing the risk of being trapped in local minima. Furthermore, by leveraging the uncertainty information provided by UT, we incorporate a risk-sensitive cost function that explicitly accounts for risk or uncertainty throughout the trajectory evaluation process, resulting in a more resilient control system capable of handling uncertain conditions.
YouTube link:
We also proposed a method called log-MPPI equipped with a more effective trajectory sampling distribution policy which significantly improves the trajectory feasibility in terms of satisfying system constraints. The key point is to draw the trajectory samples from the normal log-normal (NLN) mixture distribution, rather than from the Gaussian distribution. Furthermore, this work presents a method for collision-free navigation in unknown cluttered environments by incorporating the 2D occupancy grid map into the optimization problem of the sampling-based MPC algorithm.
YouTube link:
Variants of Markov Decision Processes:
We developed a framework called time-varying Markov Decision Process (TVMDP). The new framework does not need to increase state space or discretize time. Specifically, the TVMDP is built upon an upgraded transition model that varies both spatially and temporally, with an underlying computing mechanism that can be imagined as value iterations combining both spatial "expansion" and temporal "evolution". Such a framework is able to integrate a future horizon of environmental dynamics and produce highly accurate action policies under the spatio-temporal disturbances that are caused by, e.g, tidal and/or air turbulence.


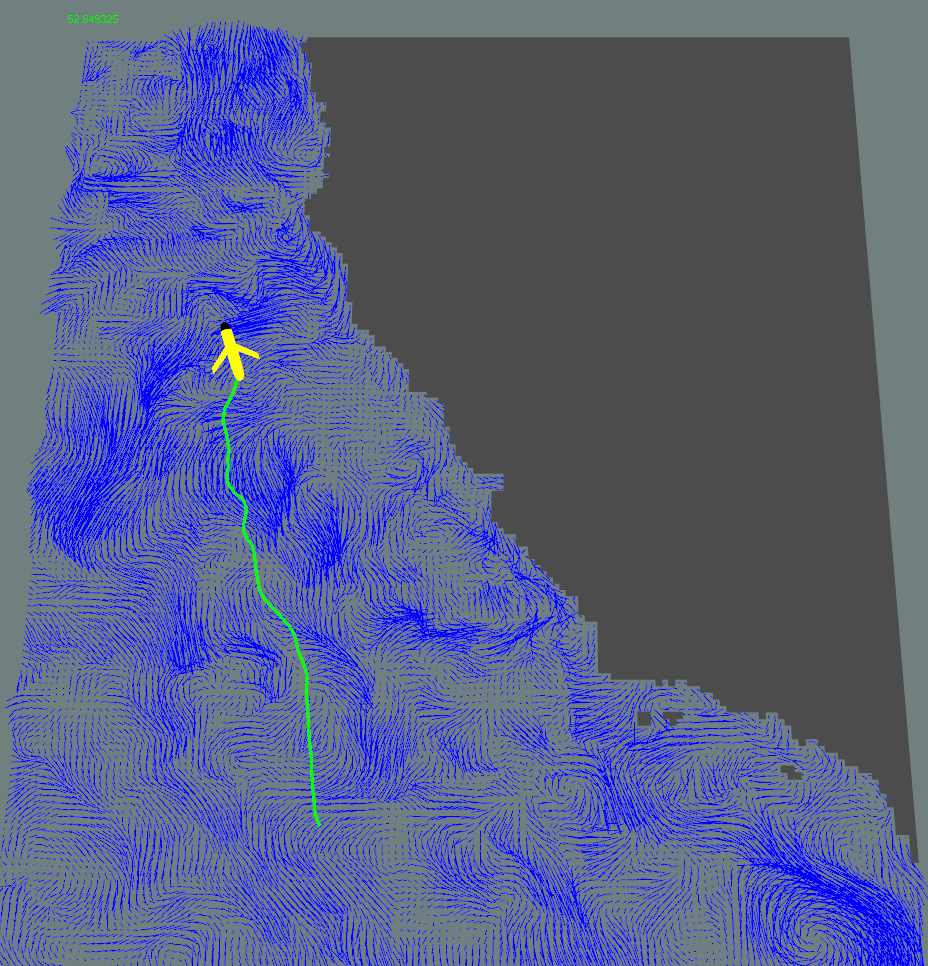
Left: flow pattern near San Francisco Bay (by F. Baart et al). Middle: without considering the time-varying aspect of disturbance, the robot's trajectory makes unnecessary detours. Right: trajectory produced by a decision-making strategy that has integrated prediction of ocean currents near southern California.
State-Continuity Approximation of Markov Decision Processes: we also developed a solution to the MDP based decision-theoretic planning problem using a continuous approximation of the underlying discrete value functions. This approach allows us to obtain an accurate and continuous form of value function even with a small number of states from a very low resolution of state space. We achieved this by taking advantage of the second order Taylor expansion to approximate the value function, where the value function is modeled as a boundary-conditioned partial differential equation which can be naturally solved using a finite element method. Our extensive simulations and the evaluations reveal that our solution provides continuous value functions, leading to better path results in terms of path smoothness, travel distance and time costs, even with a smaller state space.
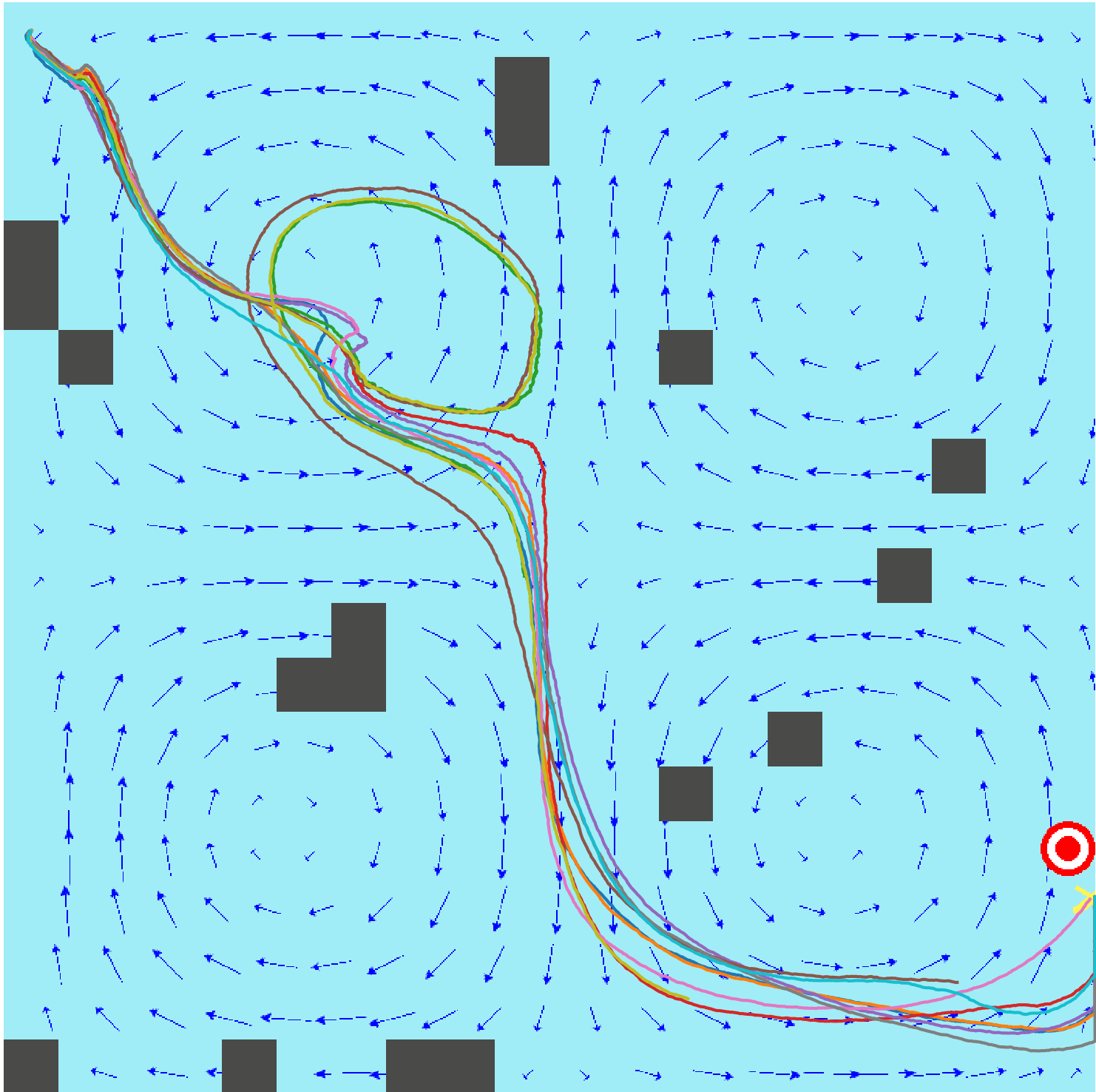
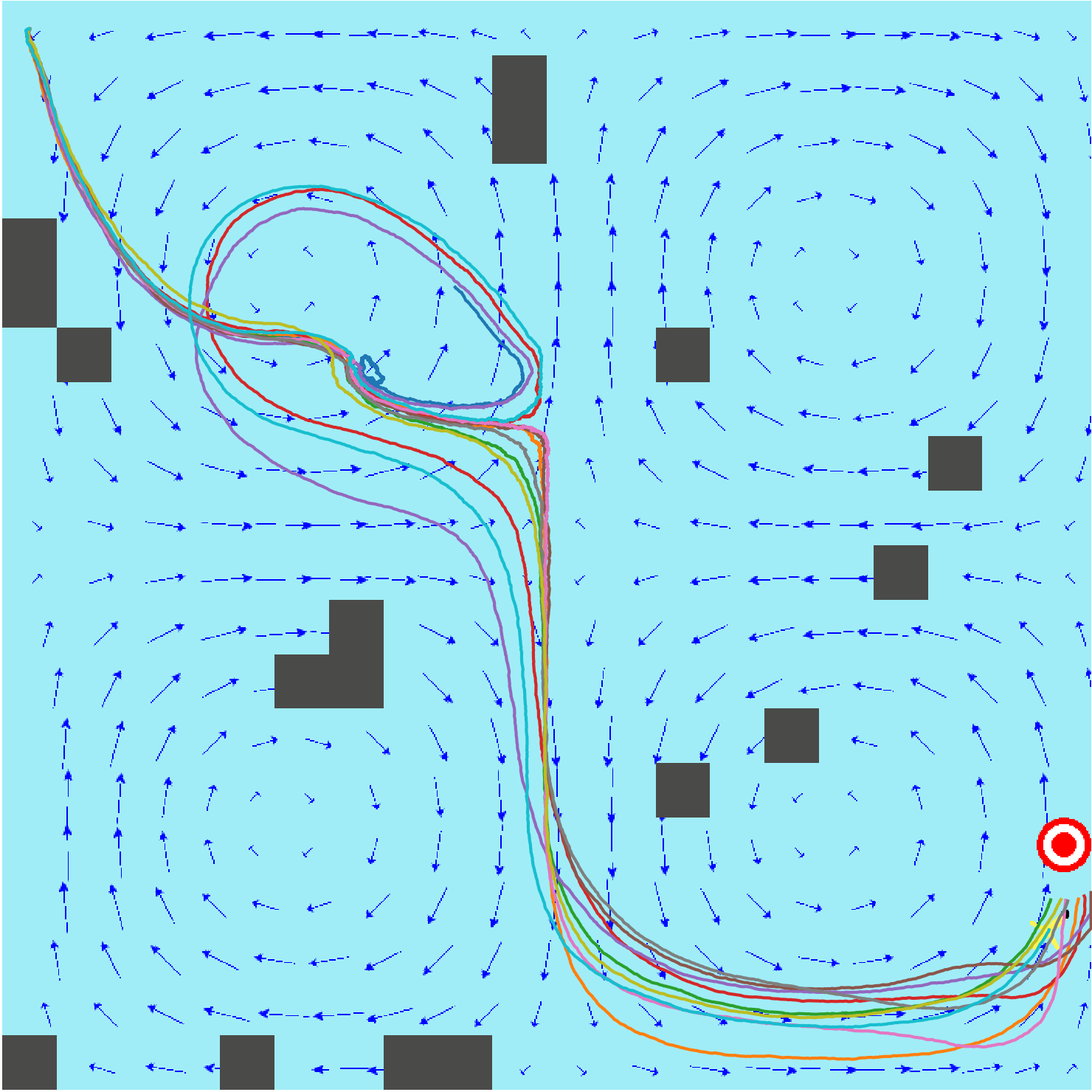
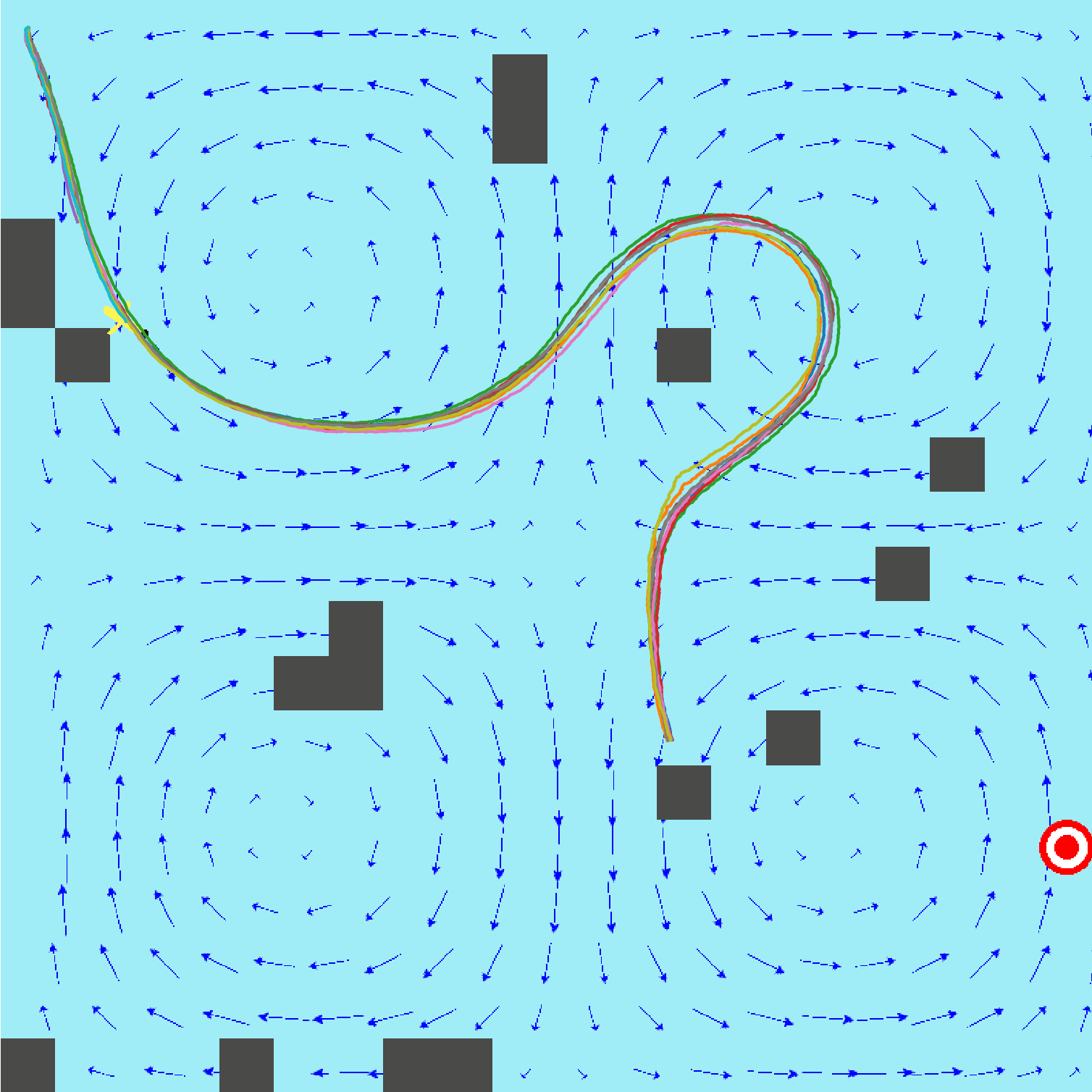
Left: MDP policy iteration with continuous value approximation by finite element analysis. Middle: MDP policy iteration with exact discrete policy iteration on high-resolution states (traditional). Right: Goal-oriented planner without motion uncertainty (policy) optimization.